Memory für die Krebsforschung
Forschende der Johannes Kepler Universität Linz haben ein „Google der Zellbiologie“ entwickelt. Was CLOOME kann und welche Chancen es bietet, dazu hat CliniCum onko mit Elisabeth Rumetshofer gesprochen.
CliniCum onko: Was ist das Besondere an CLOOME?
Elisabeth Rumetshofer: Bisher waren Bio-Imaging-Datenbanken bei ihrer Suche immer darauf angewiesen, dass die eingespielten Mikroskopie-Bilder mit manuellen Annotationen und Texten beschriftet sind. Das Besondere an unserer Arbeit ist, dass wir einen Schritt weiter gegangen sind in Richtung selbstüberwachtes Lernen, einem Teilgebiet der Künstlichen Intelligenz (KI)-Forschung. Wir stützen uns nicht auf Annotationen, sondern verwenden Daten aus einem öffentlichen Datensatz von Zellbildern mit Metadaten, um das neuronale Netzwerk zu trainieren. Dabei lernt das neuronale Netzwerk, Bilddaten mit chemischen Strukturen zu verbinden. Das Netzwerk erkennt den Zusammenhang zwischen den Strukturen von Wirkstoffen und dem Aussehen von Zellen und kann damit Effekte von Wirkstoffen vorhersagen.
Wie kommen Sie an diese Bilder?
Wir nutzen Cell Painting, einen öffentlichen Datensatz, den das Broad Institute of MIT and Harvard vor einigen Jahren herausgegeben hat. Dabei wurden Zellen einer Zelllinie mit etwa 30.000 Molekülen behandelt und das Ergebnis auf Mikroskopie-Bildern festgehalten.
Und wie funktioniert CLOOME konkret?
CLOOME besteht aus zwei neuronalen Netzwerken, eines für Zellbilder und eines für Moleküle. CLOOME bekommt eine große Anzahl an Bildern und Molekülen und muss herausfinden, welches Molekül zu welchem Bild passt – so wie bei Memory. Idealerweise lernt CLOOME nicht nur, welches Molekül welche Effekte auf welche Zelle hat, sondern kann dieses Wissen auf ähnliche Strukturen übertragen. Die beiden neuronalen Netze von CLOOME können dadurch sehr schnell mit kleineren Datensätzen an neue Aufgaben angepasst werden. Das ist auch deshalb ein Vorteil, weil es viel Rechenleistung erfordert, auf hochauflösenden Mikroskopiebildern zu trainieren.
Wie groß ist so ein Datensatz üblicherweise?
Der CP-Datensatz, den wir für CLOOME verwendet haben, hat in etwa 2 Terrabyte. Das JUMP Cell Painting Consortium des Massachusets Life Science Center hat jedoch gerade einen neuen Datensatz mit über 100 Terrabyte veröffentlicht.
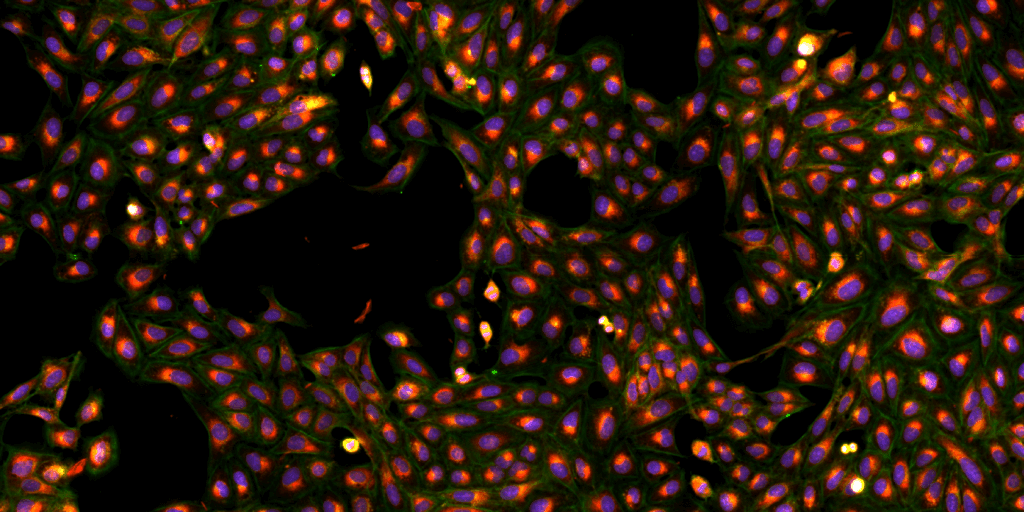
Beispiel eines Cell Painting-Mikroskopie-Bildes
In welchen Anwendungsgebieten ist CLOOME hilfreich?
Die Hauptanwendung ist die Datenbanksuche. Das Netzwerk sucht passend zu einem Bild die ähnlichsten Moleküle, das heißt, jene Moleküle, von denen das Netzwerk glaubt, dass sie die gesuchten Effekte haben. Das hat gerade für die Entwicklung von neuen Therapien und Medikamenten große Vorteile. Denn mit CLOOME kann man auch nach Alternativen suchen, wenn etwa ein Wirkstoff nicht synthetisch hergestellt werden kann oder zu teuer in der Produktion ist. Und es werden auch Moleküle vorgeschlagen, die eine andere Struktur haben, aber eine ähnliche Wirkung.
KI-Systeme sind nur so gut wie die Daten, mit denen sie gefüttert wurden. Wie sieht es mit der Datenlage in Österreich aus?
Grundsätzlich arbeiten wir viel mit öffentlichen Daten wie eben Cell Painting. Das sind meist nicht österreichische Daten, sondern internationale von Instituten oder Universitäten. In Österreich gibt es an Universitätskrankenhäusern und ähnlichen Einrichtungen aber durchaus interessante Datensätze. Prinzipiell ist es hilfreich, wenn bei der Datenakquise auch Personen involviert sind, die einen Bezug zum Machine Learning haben. Es ist oft nicht nur wichtig, dass man viele Daten hat, sondern auch welche, beziehungsweise wie die Daten gesammelt werden.
Was würden Sie sich wünschen zum Thema Datensammlung?
Es gibt schon viele Initiativen, wie zum Beispiel Jump CP, wo sehr viele Daten gesammelt wurden. Aber die Datenmenge allein ist nicht immer ausschlaggebend. Gut wäre es, wenn Daten standardisiert gesammelt werden – und zwar über Ländergrenzen hinweg. Da gibt es auch schon einige Initiativen. Ich denke, dass es halt immer schwierig ist, sobald Patienten involviert sind.
Wie gehen Sie damit um, dass die KI Diskriminierungen reproduziert oder auch falsche kausale Schlüsse zieht?
Ein neuronales Netzwerk hat kein Bewusstsein, es lernt nur nach Wahrscheinlichkeiten. Diskriminierung ist damit nicht die Schuld von neuronalen Netzwerken, sondern der verwendeten Daten. Wenn diese zu homogen sind, lernt das neuronale Netzwerk eben ein verzerrtes Bild. Umso wichtiger ist Diversität bei den Daten.
Über Elisabeth Rumetshofer
Elisabeth Rumetshofer ist Doktorandin am Institut für Machine Learning an der Johannes Kepler Universität in Linz. Gemeinsam mit Ana Sanchez-Fernandez, Sepp Hochreiter und Günter Klambauer hat sie das Paper zu CLOOME in „Nature Communications“ publiziert.